
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 큰수의 법칙
- 핵개발
- 수학적 사고
- 인터스텔라
- 최저시급 개정안
- R 기초
- 핵 개발
- 찬물샤워
- 아인슈타인
- 비율
- 유닛테스트
- 자기관리
- 산입 범위
- 통계 오류
- 최저 시급
- 동전 던지기
- 이기적 유전자
- 산입범위
- 조던피더슨
- 성악설
- t검정
- 통계오류
- R4DS
- t-test
- R 프로그래밍
- 멘탈관리
- 비행기 추락
- 비선형성
- 티모시페리스
- 선형성
- Today
- Total
public bigdata
따라하며 배우는 데이터 과학 7장 본문
7.1
-
80%의 실제 문제는 20%정도의 통계 기법으로 처리할 수 있다.
> 그 통계 기법들은 크게 선형 모형, 일반화 선형 모형, 그리고 고차원 통계학습 모형인 라쏘 모형, 랜덤 포레스트 정도이다.
| 데이터형 | 분석 기법과 R함수 | 모형 |
| 0. 모든 데이터 |
데이터 내용, 구조 파악(glimpse) |
|
| 1. 수량형 변수 | 분포시각화(hist, boxplot, density) 요약 통계량(mean, median) t-검정(t.test) |
 |
| 2. 범주형 변수(성공-실패) | 도수 분포(table, xtabs) 바그래프 barplot 이항검정 binom.test |
X ~ binom(n, p) |
| 3. 수량형 x, 수량형 y | 산점도 plot 상관계수 cor 단순회귀 lm 로버스트 회귀 lqs 비모수회귀 |
? 책에서 여기 수식이 뜻하는 바가 뭔지 모르겠다 |
| 4. 범주형 x, 수량형 y | 병렬상자그림 boxplot 분산분석 anova, lm |
yi가 iid |
| 5. 수량형 x, 범주형(성공-실패) y | 산점도/병렬상자그림 plot, boxplot 로지스틱 회귀분석 glm(family='binom') |
7.2 모든 데이터에 행해야 할 분석
-
데이터 내용, 구조, 타입을 파악한다 dplyr::glimpse 함수가 유용하다, str, head
-
데이터의 요약 통계량을 파악한다 summary가 유용하다
-
결측치가 있는지 살펴본다. summary함수는 결측치의 개수를 보여준다
-
무작정 시각화를 해본다 plot pairs를 돌려보면 좋다. 데이터가 많은 경우 dplyr::sample_n함수를 사용해 표본화한다. 변수가 많을 때는 10열씩 구분하여 살펴보는 것도 유용하다.
7.3 수량형 변수의 분석
일변량 변수에 대한 통계량 분석은 크게 다음과 같다.
- 데이터 분포의 시각화 : 히스토그램, 상자그림, 확률밀도함수로 분포 살펴보기, hist, boxplot, geom_density
- 요약 통계량 계산 : summary, mean, median, var, sd, mad, quantile
- 데이터의 정규성 검사 : qqplot, qqline으로 정규분포와 얼마나 유사한지 알 수 있다
- 가설검정과 신뢰구간 : t.test함수를 사용하면 일변량 t검정, 신뢰구간을 구할 수 있다. 실제로 데이터의 분포가 정규분포가 아니더라도 큰 문제가 되지 않는다(중심극한정리 때문인지, x평균의 분포가 정규분포가 아니여도 문제가 안된다는 말인지, 책에서는 아마 x평균의 분포가 정규분포가 아니여도 큰 문제가 아니라고 소개하는 것으로 보인다)
- 이상점 찾아보기 : 이상점을 찾고, 제대로 된 값이 아니라면(입력 실수) 제거하면 되고, 제대로 입력된 값이라면 함부로 제거하면 안되기 때문에 로버스트 통계량(이상점에 영향을 적게 받는 통계량)을 사용하여 데이터를 잘 대표하는 통계값을 사용해야 한다. Ex. 평균 대신 중앙값, 표준편차 대신 MAD(Median Absolute Deviance)
7.3.1 일변량 t-검정

위와 같은 단측 검정을 시행하고자 한다고 해보자. R의 t.test() 사용
library(tidyverse)
hwy = mpg$hwy
n <- length(hwy)
mu0 <- 22.9
t.test(hwy, mu = mu0, alternative = "greater")
##############t-test 결과##############
> t.test(hwy, mu = mu0, alternative = "greater")
One Sample t-test
data: hwy
t = 1.3877, df = 233, p-value = 0.08328
alternative hypothesis: true mean is greater than 22.9
95 percent confidence interval:
22.79733 Inf
sample estimates:
mean of x
23.44017 t.test 결과를 보면 p-value 값이 0.08328으로 0.05보다 크다 그러므로 귀무가설을 기각하지 못하므로 대립가설을 채택하지 못한다. 즉. 귀무가설 하에서(실제 모 평균 고속도로 연비가 22.9라고 할 때) 우리가 관측한 것 만큼 큰 표본평균값과 t 통계량 값이 관측될 확률이 8.3%라는 것이다. 고속도로 연비가 22.9보다 크다고 결론(귀무가설을 기각할 만큼)지을 만한 증거가 충분하지 않다고 할 수 있다. 반대 상황일 때는 반대로 해석하면 되고, 양측 검정일 때는 ? --> 귀무가설 하에서 우리가 관측한 통계량 만큼 극단적인 큰 값(절대값)이 발생할 확률이 p-value이다 라고 말하면 된다. - 오류가 있다면 댓글 달아 주시면 ... 함께 공부합시다)
t-test의 정규성 관련 정리
- 표본의 갯수가 >=30 이면 t.test 그냥 사용하면 된다(중심극한정리)
- 표본의 갯수가 <30 이면 데이터의 분포를 그려보고, 혹은 정규성 검정을 통해서 데이터가 정규분포를 따르는지 검정이 필요하다. 그렇지만 데이터가 정규분포를 그리지 않아도 t-test를 사용해도 큰 무리는 되지 않는다. 하지만 엄격하게, 이론적으로는 데이터가 정규분포를 따르는 것을 가정하고 t-test가 만들어진 것을 잊지는 말아야 한다.
7.3.2 이상점과 로버스트 통계 방법
이상점을 찾는 가장 쉬운 방법은 상자그림을 살펴보는 것이다. 상자그림에서 이상점은 [Q1-1.5*IQR, Q3+1.5*IQR]구간 바깥의 값들이다. IQR은 inter-quartile range(Q3-Q1)을 나타낸다.
boxplot을 그릴 때 주의할 것이 있는데 수염(whisker)는 이상점이 아닌 값들 중에서 가장 크고 작은 값들까지만 이어진다.

위 그림의 limite inferior는 [Q1-1.5*IQR, Q3+1.5*IQR]구간 내에서 가장 작은 값, 가장 큰 값 까지 연결된 것이다.
로버스트 통계 방법은 이상점의 영향을 적게 받는 절차다. 평균 대신 중앙값, 표준편차 대신 MAD를 사용한다.
7.4 성공-실패값 범주형 변수의 분석
해당 챕터와 같은 데이터를 접하면 아래와 같이 분석한다.
- 요약 통계량 계산 : table, xtabs, prop.table(상대도수)
- 데이터 시각화 : barplot이 유용
- 가설검정과 신뢰구간 : binom.test를 구하면 성공률에 대한 검정과 신뢰구간을 구할 수 있다.Ex. 여론조사
지지율이 50%인 (p = 0.5) 시뮬레이션 데이터를 만들고 위에서 언급한 내용을 돌려보자
set.seed(1606)
n <- 100
p <- 0.5
x <- rbinom(n, 1, p)
x
x <- factor(x, levels = c(0, 1), labels = c("no", "yes"))
table(x)
> table(x)
x
no yes
46 54
prop.table(table(x))
> prop.table(table(x))
x
no yes
0.46 0.54
barplot(table(x))
우리는 실제 '지지율'이 50%인 것을 알고 있지만, 모른다고 생각하고 다음의 가설을 검정한다고 생각해 보자
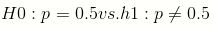
binom.test로 쉽게 신뢰구간과 가설검정을 시행할 수 있다.
binom.test(x=length(x[x=='yes']),
n = length(x),
p=0.5,
alternative = "two.sided")
> binom.test(x=length(x[x=='yes']),
+ n = length(x),
+ p=0.5,
+ alternative = "two.sided")
Exact binomial test
data: length(x[x == "yes"]) and length(x)
number of successes = 54,
number of trials = 100,
p-value = 0.4841
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.4374116 0.6401566
sample estimates:
probability of success
0.54 p값은 0.4841 귀무가설하에서 주어진 데이터만큼 극단적 데이터를 관측할 확률은 48%이다. 추가로 만약에 48%로 높은 확률이지만 기각하기로 결정했다면 해당 p-value는 귀무가설이 참인데 아니라고 할 확률48%라고 말할 수도 있지 않은가?!!
7.4.1 오차한계, 표본 크기, sqrt(n)의 힘
오차한계는 주어진 신뢰수준에서 신뢰구간의 크기의 절반으로 주어진다. 즉. 신뢰구간이[0.437, 0.640]이라면 오차한계는 (0.640-0.437)/2 = 0.101이다.
만약 표본이 100개가 아닌 100배큰 10,000이고 이 중 5,400이 '성공'이라면 신뢰구간은 어떻게 될까
> binom.test(x=5400, n=10000)
Exact binomial test
data: 5400 and 10000
number of successes = 5400,
number of trials = 10000,
p-value = 1.304e-15
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.5301711 0.5498056
sample estimates:
probability of success
0.54 아래는 모평균 추정에서의 신뢰구간이다. 식을 보면 표본평균 오른쪽 부분이 오차한계이다. 다음 식에서 상한에서 하한을 빼 보면 오차한계는 sqrt(n)에 반비례하는데 즉. 표본이 100배 커지면 오차한계는 10배 줄어든다.

그리고 표본이 100개 일 때 데이터가 10개 추가되는 효과와 표본이 1,000개 일 때 추가되는 표본의 효과는 다르다. 1,000개에서 추가되는 10개의 데이터의 효과는 100개 일 때에 비해서 작다.
신문기사의 여론조사는 보통 표본 크기와 오차한계를 보고한다. 미국 오바마 대통령의 지지율 조사가 Gallup, Fox의 차이는 59, 57이라고 할 때 큰 차이가 있어 보이지만 오차한계가 3.1%라고 한다면 오차 범위 내에 있다고 볼 수 있다.
7.6 수량형x, 수량형 y의 분석
다음 절차에 따라 데이터를 분석하면 된다.
- 산점도를 통해 관계의 모양을 파악한다. plot, geom_point를 활용한다. 중복치가 많을 때는 jitter를 사용한다. 데이터수가 너무 많을 때는 alpha옵션을 사용하거나 표본화한다. 관계가 선형인지, 강한지 약한지, 이상치는 있는지 등을 파악한다.
- 상관계수를 계산한다. 상관계수는 선형 관계의 강도만을 재는 것을 유의해야 한다.
- 선형 모형을 적합한다. 잔차의 분포를 살펴보고 전차에 이상점은 있는지 살펴본다. 잔차가 예측변수에 따라 다른 분산을 갖지는 않는지
- 이상치가 있을 때는 로버스트 회귀분석을 사용
- 비선형 데이터에는 LOESS등의 평활법을 사용한다.
상관계수는 이상치의 영향을 많이 받으므로 로버스트한 통계량인 켄탈의 타우나, 스피어맨의 로를 계산하는 것도 좋다.
상관계수는 선형 관계가 존재할 때 해당 선형 관계의 강도가 어떤지 알 수 있다. 선형 관계를 가지는지 아닌지 꼭 확인해야 한다. 상관계수가 높아도 선형 관계가 아닌 경우에 대해 아래 그림을 보자.

위 그림을 보면 상관계수는 선형일때 선형의 강도를 나타내는 것이지, 선형인지 아닌지 판단해주지 않는다는 사실을 알 수가 있다.
7.6.3 선형회귀 모형 적합
회귀모델은 여러 설명변수를 사용, 수량형 반응변수를 예측하기 위한 가장 간단하지만 유용한 모형이다. R에서 lm, summary.lm은 선형 모형을 최소제곱법으로 추정한다. 즉, 잔차의 제곱합을 최소화하는 최소화하는 회귀계수를 구한다.
lm.summary는 각 추정치와 더불어 각 모수값이 0인지 아닌지에 대한 t검정 결과를 보여준다. 회귀계수가 0인지 아닌지에 대해서
library(tidyverse)
hwy_lm <- lm(hwy~cty, data = mpg)
summary(hwy_lm)
> summary(hwy_lm)
Call:
lm(formula = hwy ~ cty, data = mpg)
Residuals:
Min 1Q Median 3Q Max
-5.3408 -1.2790 0.0214 1.0338 4.0461
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.89204 0.46895 1.902 0.0584
cty 1.33746 0.02697 49.585 <2e-16
(Intercept) .
cty ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.752 on 232 degrees of freedom
Multiple R-squared: 0.9138, Adjusted R-squared: 0.9134
F-statistic: 2459 on 1 and 232 DF, p-value: < 2.2e-16위 결과를 보면 cty변수는 p-value가 매우 작아 통계적으로 유의한 결과를 가진다. 즉, 만약 hwy가 cty와 선형 관계가 전혀 없었다면 우리가 관측한 만큼의 t-값을 관측하는 것은 실질적으로 불가능하다.
7.6.4 모형 적합도 검정
모형의 적합도를 이해하기 위해서는 선형 모형에서 제곱합의 분할을 이해하는 것이 도움이 된다.

- SST : 모형화 전의 반응변수의 변동
- SSR : 회귀분석 모형으로 설명되는 반응변수의 변동
- SSE : 모형으로 설명되지 않는 반응변수의 변동

위 식은 결정계수라고 불리며, 반응변수의 총 변동 중 얼마만큼이 선형모형으로 설명이 되는지 나타낸다. 0-1사이의 값이고 1에 가까울수록 설명변수의 설명력이 높음을 나타낸다. 참고로 단순회귀 모형일 경우에는 R-Squared의 값은 피어슨 상관계수의 제곱과 같다

위 식은 조정된 결정계수인데 기존 결정계수는 회귀모델에 쓸모없는 변수라도 추가될 수록 결정계수의 값이 즉. 모델의 설명력이 높아진다. 그래서 여러 모델끼리 성능을 비교할 때 변수가 많이 들어간 모델이 설명력이 높다고 설명한다. 그렇기 때문에 변수의 개수를 모델의 설명력에 반영한 조정된 결정계수가 필요하다.
7.6.5 선형회귀 모형 예측
library(tidyverse)
hwy_lm = lm(hwy~cty, data = mpg)
predict(hwy_lm)
resid(hwy_lm)
predict(hwy_lm, newdata = data.frame(cty = c(10, 20, 30)))
predict(hwy_lm, newdata = data.frame(cty = c(10, 20, 30)), se.fit = TRUE)위의 예시는 주어진 데이터에 대한 추정량과 잔차뿐 아니라 새로운 데이터 cty = 10, 20 , 30에 대한 예측값, 그리고 예측오차를 계산한다
7.6.6 선형회귀 모형의 가정 진다
이론적으로 선형회귀 결과가 의미 있으려면 다음의 조건이 충족되어야 한다
- x와 y의 관계가 선형이다
- 잔차의 분포가 독립이다
- 잔차의 분포가 동일하다
- 잔차의 분포가 평균이 0 이고 분산이 일정한 분포를 따른다
가장 만족하기 어려운 조건 4는 다행이도 아주 중요하지는 않다. 하지만 조건 3이 어긋나는 경우, 특히 분산이 x값에 따라 변하는 것은 추정치와 오차의 유효성에 영향을 준다. 이런 오차 분포를 이분산성 오차 분포라고 부른다. 이런 경우 가중회귀분석 기법을 이용하면 된다. 그리고 조건 1,2가 어긋난다면 모든 모수의 의미가 왜곡되게 되므로 시각적으로 잔차의 분포가 x변수에 따라 그리고, y 변수에 따라 변하는지 살펴볼 필요가 있다. 이런 검토를 회귀분석 진단이라고 한다.
회귀분석 진단 중 중요한 수치 중 하나는 레버리지(leverage)다 복잡한 수식은 생략하고 회귀계수와 예측값은 변수 y와의 행렬 곱의 관계로 나태낼 수 있는데 y를 나타내는 행렬을 제외한 나머지 부분을 영향행렬이라고 하는데 이 행렬의 i번째 대각원소를 i번째 레버리지라고 한다. 만약 i 번째 레버리지가 크다면 i번째 y값의 작은 변화에도 예측값이 y 방향으로 더 많이 끌려가게 된다. 즉. 더 많이 영향을 받게 되는 것이다.

위 그림은 선형 모형 진단 플롯이다. Residual vs Fitted 그림은 잔차의 분포가 예측값과 독립적인지를 확인하는 데 사용된다. Normal Q_Q그림은 표준화된 잔차의 분포가 정규분포에 가까운지를 확인한다. Scale-Location그림은 잔차의 절댓값의 제곱근과 예측값 사이의 관계를 보여준다. Residuals vs Leverage는 표준화된 잔차와 레버리지 간의 관계를 보여준다. - 이 부분은 ISLR 잔차 부분을 참고하는 것이 좋겠다. 회귀분석을 써먹을 때
7.6.7 로버스트 선형회귀분석
수량형 변수에 이상치가 있을 경우에는 로버스트 통계 방법을 사용하는 것이 유용할 수 있다. 선형회귀분석의 모수 추정값은 잔차의 분포에서 이상치가 있을 때 지나치게 민감하게 반응하게 된다. 이는 모수를 추정할 때 최소제곱 방법을 사용하기 때문이다. MASS 패키지의 lqs함수를 통해 데이터 중 '좋은'관측치만 적합에 사용하도록 하자. lqs는 제곱오차의 floor((n+p+1)/2)을 최소화 한다. 아래는 실행 예시다
library(MASS)
set.seed(123)
lqs(stack.loss ~ ., data = stackloss)
lm(stack.loss~. ,data = stackloss)
> lqs(stack.loss ~ ., data = stackloss)
Call:
lqs.formula(formula = stack.loss ~ ., data = stackloss)
Coefficients:
(Intercept) Air.Flow Water.Temp Acid.Conc.
-3.581e+01 7.500e-01 3.333e-01 3.140e-16
Scale estimates 0.8482 0.8645
> lm(stack.loss~. ,data = stackloss)
Call:
lm(formula = stack.loss ~ ., data = stackloss)
Coefficients:
(Intercept) Air.Flow Water.Temp Acid.Conc.
-39.9197 0.7156 1.2953 -0.1521 로버스트 방법과 회귀 분석을 비교해 보면 큰 차이를 보이는데 특히. 산농도 변수의 효과는 거의 없다.
7.6.8 비선형/비모수적 방법, 평활법과 LOESS
비선형적인 x-y관계를 추정해내기 위해서는 비선형회귀분석을 사용하거나 다항회귀를 사용해야 한다. 하지만 이런 모형모다 손쉽게 사용할 수 있는 것은 모형에 아무 가정도 하지 않는 평활법이다.

R에서는 loess 함수로 간단히 실행할 수 있다.
plot(hwy~displ, data = mpg)
mpg_lo <- loess(hwy~displ, data = mpg)
mpg_lo
summary(mpg_lo)
xs <- seq(2, 7, length.out = 100)
mpg_pre <- predict(mpg_lo, newdata = data.frame(displ=xs), se = TRUE)
lines(xs, mpg_pre$fit)
lines(xs, mpg_pre$fit - 1.96*mpg_pre$se.fit, lty = 2)
lines(xs, mpg_pre$fit + 1.96*mpg_pre$se.fit, lty = 2)
시각화만 필요하면 쉽게 geom_smooth를 사용하면 된다.
이 후의 내용이 필요한 경우 7.7 장 부터는 책을 이용하자. 계속해서 정리하는 건 비효율적이라 생각돼서 .. 그만 정리한다. ㅎㅎ
'데이터분석 > 따라하며 배우는 데이터 과학' 카테고리의 다른 글
| 따라하며 배우는 데이터 과학 6장(통계의 기본 개념 복습)_중요 (0) | 2019.07.10 |
|---|---|
| 따라하며 배우는 데이터 과학 5장 (코딩 스타일) (0) | 2019.07.09 |
| 따라하며 배우는 데이터 과학 4장 (0) | 2019.07.06 |
| 따라하며 배우는 데이터 과학 3장(데이터 취득과 데이터 가공:SQL과 dplyr) (0) | 2019.07.03 |
| 따라하며 배우는 데이터 과학 2장 (0) | 2019.07.03 |



