
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 조던피더슨
- 아인슈타인
- 찬물샤워
- 산입 범위
- 통계 오류
- 산입범위
- 수학적 사고
- 멘탈관리
- t-test
- 비행기 추락
- R4DS
- 성악설
- 핵개발
- 통계오류
- 핵 개발
- 최저 시급
- 비율
- 유닛테스트
- 이기적 유전자
- 큰수의 법칙
- t검정
- 최저시급 개정안
- 자기관리
- 비선형성
- R 기초
- 선형성
- 인터스텔라
- 티모시페리스
- 동전 던지기
- R 프로그래밍
- Today
- Total
public bigdata
따라하며 배우는 데이터 과학 4장 본문
4장 데이터 분석 순서
-
glimpse 함수를 통해 데이터를 살펴본다.

-
간단한 통계량을 계산해본다. [summary 함수 활용]
-
시각화 해본다.
데이터의 정규성, 등분산성이 필요한 경우에는 log, sqrt 변환을 통해서 가정을 만족시켜주는 것이 중요하다.
-
시각화의 중요성
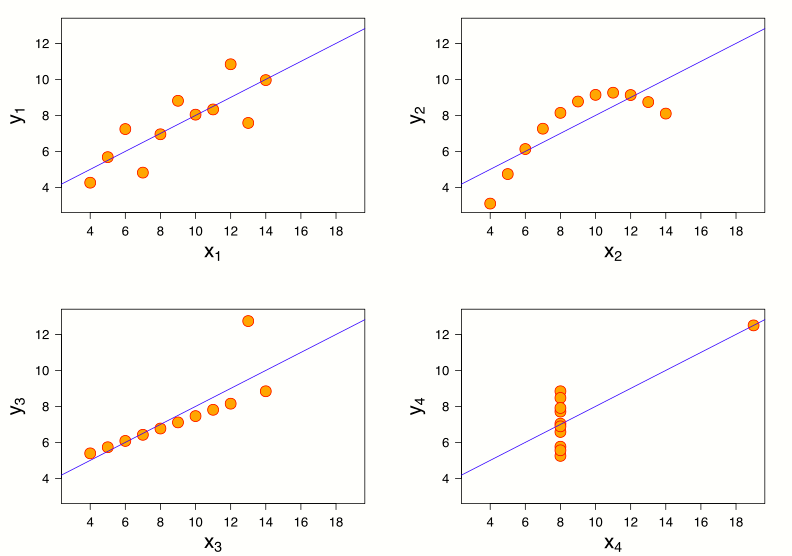
아래 그림은 앤스콤의 사인방이라 불리는 시각화 예이다. 놀랍게도 네 그래프의 데이터 모두 동일한 평균, 분산, 상관관계, 선형 모형을 가지고 있다. 그럼에도 불구하고 데이터가 다른 패턴을 보인다. 이렇듯 데이터 분석과 함께 시각화를 함께 살펴보는 것이 정말 중요하다.
4.2.1 ggplot error bar 그리기
df <- data.frame(gp = factor(rep(letters[1:3], each = 10)),
y = rnorm(30))
ds <- df %>%
group_by(gp) %>%
summarise(mean = mean(y), sd = sd(y))
ggplot() +
geom_point(data = df, aes(x = gp, y = y)) +
geom_point(data = ds, aes(x = gp, y = mean),
colour = 'red', size = 3) +
geom_errorbar(data = ds, aes(x = gp,
ymin = mean - sd, ymax = mean + sd),
colour = 'red', width = 0.4)

※ 해당 방법 말고도 stat_summary 함수를 통해서 그리는 방법도 있는데 앤디필드 책에서 한 번 찾아보겠다.
ggplot() +
geom_point(data = df, aes(x = gp, y = y)) +
geom_point(data = ds, aes(x = gp, y = mean),
colour = 'red', size = 3) +
stat_summary(data = df,
aes(x = gp, y = y),
fun.data = mean_cl_normal,
geom = 'errorbar'
)※ 모든 geom 함수들은 각기 다른 default stat함수를 통해서 데이터를 계산받고 해당 데이터를 통해서 plot을 그리기 때문에 반대로 stat함수로 모든 geom함수를 그릴 수도 있다. 여기서 다른 점은 fun.data인자에 적용된 mean_cl_normal은 y값을 정규분포로 가정한 뒤에 95신뢰구간을 구하여 준뒤에 해당 데이터를 geom_errorbar에 전달하여 그리기 때문에 위의 그래프와 구간이 다르다.
4.1 한 수량형 변수
> 많은 경우에 히스토그램으로 데이터를 파악하기에 충분하다. 히스토그램을 통해 파악할 내용은 아래와 같다.
-
이상점은 없는가
-
분포의 모양은 어떠한가
-
어떤 변환을 하면 데이터가 종모양에 가까워지는가
-
히스토그램이 너무 자세하거나 거칠지 않은가 (이런 경우 binwidth 값을 조정한다)
4.2 한 범주형 변수
> 한 범주형 변수의 시각화는 막대그래프가 유일하다
-
도수 분포, 상대도수, 퍼센트
-
group_by + tally 또는 count 함수를 통해 비율을 구할 수 있다
4.3 두 수량형 변수
> 두 수량형 변수의 시각화는 산점도를 사용한다. R에서는 pairs 함수를 사용한다.
-
점들에 중복된 관측치가 있을 때는 geom_jitter를 통해서 점들을 조금 흩어준다.
-
점들의 밀도가 너무 높을 때는 alpha값을 줄여준다
-
데이터의 개수가 너무 많을 때는 천 여 개 정도의 점들을 표본화한다
-
일변량 데이터의 예처럼 x나 y 변수에 제곱근 혹은 로그변환이 필요한지 살펴본다
-
데이터의 상관 관계가 강한지 혹은 약한지 살펴본다
-
데이터의 관계가 선형인지 혹은 비선형인지 알아본다
-
이상점이 있는지 살펴본
4.3.4 수량형 변수와 범주형 변수
> x변수가 범주형일 경우에는 병렬 상자그림으로 데이터를 시각화한다.
병렬상자그림을 사용할 때 주의할 점과 살펴볼 내용은 다음과 같다
-
reorder명령처럼 통계량에 기반을 둔 범주의 순서를 정할 수도 있다, factor(levels=)명령을 통해 수동으로 정하는 것이 나을 수도 있다.
-
수량형 y변수의 제곱근과 로그변환이 도움이 될 수 있다.
-
수량형 y변수의 분포가 어떤지 살펴볼 수 있다.
-
이상점이 있는가
-
x 범주 그룹의 관측치는 충분한가
-
x축과 y축을 교환할 필요는 없는가 (coord_flip함수 사용 가능)
4.3.5 두 범주형 변수
-
도수 분포를 알아내기 위해서 xtabs 함수를 사용한다
-
시각화하기 위해서는 mosaicplot을 사용한다
-
xtabs 고차원 행렬로 정리되면 모자익플롯으로 시각화할 수 있다
mosaicplot(Titanic, main = "Survival on the Titanic", color = TRUE)
-
위 플롯에 대한 자세한 정보는 해당 링크를 이용하기 바란다 ※ 출처 또한 해당 링크
R : 모자이크 플롯-mosaic plot (개념 및 예제)
모자이크 플롯 (mosaic plot) 모자이크 플롯(mosaic plot)은 무엇일까요? 2원 3원 교차표의 시각화입니다. 따라서 전체 정사각 도형을 교차표의 행 빈도에 비례하는 직사각 도형으로 나누어 줍니다. 그 다음에, 다..
jjeongil.tistory.com
-
범주별로 더 많은 변수를 보여주려고 한다면 facet_wrap함수를 사용하면 된다
4.4 시각화 과정의 몇 가지 유용한 원칙
-
데이터에 대한 설명을 읽는다. 문맥을 파악한다.
-
glimpse 함수로 데이터구조를 파악한다. 행의 개수는?, 변수의 타입은?
-
pairs 산점도 행렬로 큰 크림을 본다. 행의 수가 너무 클 경우에는 sample_n함수로 표본화한다. 변수의 수가 너무 큰 경우에는 10여개 이하의 데이터별로 살펴본다.
-
주요 변수를 하나씩 살펴본다. 수량형 변수는 히스토그램, 범주형 변수는 막대그래프를 사용한다. geom_histogram, geom_bar를 사용한다.
-
두 변수 간의 상관 관계를 살펴본다. geom_point, geom_boxplot을 사용한다.
-
고차원의 관계를 연구한다. geom_* 함수의 속성을 활용한다. 적절할 경우에는 facet_wrap함수를 사용한다.
-
양질의 의미 있는 결과를 얻을 때까지 위의 과정을 반복한다
-
의미 있는 플롯은 문서화한다. 플롯을 생성한 코드도 버전 관리한다.
'데이터분석 > 따라하며 배우는 데이터 과학' 카테고리의 다른 글
| 따라하며 배우는 데이터 과학 7장 (0) | 2019.08.01 |
|---|---|
| 따라하며 배우는 데이터 과학 6장(통계의 기본 개념 복습)_중요 (0) | 2019.07.10 |
| 따라하며 배우는 데이터 과학 5장 (코딩 스타일) (0) | 2019.07.09 |
| 따라하며 배우는 데이터 과학 3장(데이터 취득과 데이터 가공:SQL과 dplyr) (0) | 2019.07.03 |
| 따라하며 배우는 데이터 과학 2장 (0) | 2019.07.03 |



