
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 산입범위
- t검정
- 큰수의 법칙
- 성악설
- 동전 던지기
- 산입 범위
- R 기초
- 핵 개발
- 멘탈관리
- 최저 시급
- 통계오류
- 유닛테스트
- 비선형성
- 조던피더슨
- 수학적 사고
- 비율
- R 프로그래밍
- 찬물샤워
- 선형성
- t-test
- 이기적 유전자
- 핵개발
- 자기관리
- 티모시페리스
- R4DS
- 통계 오류
- 아인슈타인
- 최저시급 개정안
- 비행기 추락
- 인터스텔라
- Today
- Total
public bigdata
R4DS (R for DataScience) 1장 본문
R4DS (R for DataScience) 1장
public bigdata 2019. 11. 3. 15:38저작권 : "R for DataScience by Hadley Wickham and Garrett Grolemund(O'Reilly). Copyright 2017 Garrett Grolemund, Hadley Wickham, 978-1-491-91039-9
1.1 들어가기
시작하기 전 ggplot2의 이론적 토대에 대해 더 자세히 알고 싶다면 The Layered Grammar of Graphics를 읽을 것을 추천한다.
1.2.3 그래프 작성 템플릿
ggplot(data=<데이터>)+
<지옴 함수>(mapping=aes(<매핑모음>))ggplot을 하면 좌표 시스템이 생성되고 레이어를 추가할 수 있다.
1.3
library(tidyverse)
ggplot(data = mpg)+
geom_point(mapping = aes(x=displ, y=hwy, color = class))
color, colour(영국식) 동일한 인자명이다. 심미성을 변수에 매핑하기 위해서는 aes()내부에 심미성 이름을 변수 이름과 연결해야 한다. ggplot2는 변수의 고유한 값에 심미성의 고유한 수준을 자동으로 지정하는데, 이 과정을 스케일링(scailing)이라고 한다.
우측 상단의 이상값들을 보면 이상값 중 다수가 2인승 차임을 보여준다. 엔진크기가 크지만 2인승차여서 연비가 좋을 것으로 보인다.
shape 인자를 사용할 때 한번에 여섯 개의 모양만 사용하므로 추가되는 그룹들은 플롯되지 않고 그려진다.
아래와 같이 지옴 심미성의 속성을 수동으로 설정할 수 있다.
library(tidyverse)
ggplot(data = mpg)+
geom_point(mapping = aes(x=displ, y=hwy), color = "blue")
aes() 바깥에서 정의하면 수동으로 지정이 가능하다.
1.3.1 연습문제
6번
library(tidyverse)
ggplot(data = mpg)+
geom_point(mapping = aes(x=displ, y=hwy, color = displ<5))
color = displ<5 이 부분을 보면 displ을 활용한 조건식이 지정되었는데 그래프에서 보이듯이 조건식에 대한 결과 TRUE/FALSE를 기반으로 심미성을 지정하게 된다.
5번 stroke 심미성의 역할은 무엇인가? 어떤 모양과 함께 작동하는가?(?geom_point를 사용하라)
ggplot(mtcars, aes(wt, mpg)) +
geom_point(shape = 24, colour = "black", fill = "white", size = 5, stroke = 10)
shape(21번 예) stroke 인자는 경계선의 너비를 결정한다. shape 중에서 속성, 속이 찬 모양인(21-24)는 color, fill 구분해서 따로 적용이 가능하다.
1.5 면분할
범주형 변수에 특히 유용한 방법, 플롯을 면분할(facet, e데이터 각 서브셋을 표시하는 하위 플롯)로 나누는 것이다. 면분할을 하려면 facet_wrap()을 사용하면 된다.
ggplot(mpg, aes(displ, hwy)) +
geom_point(shape = 21, colour = "black", fill = "white", size = 3)+
facet_wrap(~class, nrow = 2)두 변수 조합으로 면분할은 dacet_grid()를 사용한다.
ggplot(data=mpg)+
geom_point(mapping = aes(x=displ,y=hwy))+
facet_grid(drv~cyl)
facet_grid()에서 행 또는 열 구분을 하고 싶지 않다면 다음과 같이 사용한다.
ggplot(data=mpg)+
geom_point(mapping = aes(x=displ,y=hwy))+
facet_grid(.~cyl)1.5.1 연습문제
5번
?facet_wrap을 읽어라 nrow의 역할은 무엇인가? ncol은 어떤 일을 하는가? 개별 패널의 배치를 조정할 수 있는 다른 방법은 무엇인가? facet_grid()에는 nrow, ncol 인수가 왜 없는가?
facet_wrap은 한 변수에 의해서 plot을 나누어 주는 함수이기 때문에 nrow 또는 ncol이 필요하다.
facet_grid는 두 변수들의 고유한 값에 의해서 plot을 나누어 주는 것이 목적이기 때문에 nrow 또는 ncol이 필요하지 않다.
facet_grid를 살펴보면 vars라는 함수가 등장하는데, vars는 quoting function의 한 종류이다. vars는 plot의 데이터셋 내부에서 평가될 수 있도록 인용하는 함수이다.
6번
facet_grid를 사용할 때, 대개의 경우 고유 수준이 더 많은 변수를 열로 두어야 한다. 왜인가?
그 이유는 plot을 가로로 배치하면 열에 더 많은 공간이 생긴다고 한다. (그냥 이렇게만 알아두자) 예시는 아래와 같다.
ggplot(data=mpg)+
geom_point(mapping = aes(x=displ,y=hwy))+
facet_grid(drv~cyl)
1.6 기하 객체
1) geom_smooth()는 linetype으로 매핑된 변수의 고윳값마다 다른 형태의 선을 그릴 수 있다.
ggplot(data = mpg)+
geom_smooth(mapping = aes(displ, hwy, linetype = drv))

2) ggplot2는 group 심미성을 설정하여 다중 객체를 그릴 수 있다. group 심미성 인자는 기본적으로 범례를 추가하거나 구별시켜주는 기능들을 추가하지 않기 때문에, 이 기능을 활용하면 편하다.
library(tidyverse)
library(gridExtra)
p1 <- ggplot(data = mpg)+
geom_smooth(mapping = aes(displ, hwy))
p2 <- ggplot(data = mpg)+
geom_smooth(mapping = aes(displ, hwy, group=drv))
p3 <- ggplot(data = mpg)+
geom_smooth(mapping = aes(displ, hwy, color = drv),
show.legend = FALSE)
gridExtra::grid.arrange(p1, p2, p3, nrow=1)
group, color 심미성 인자 간에 차이는 group은 color와 달리 자동적으로 범례를 추가하지 않으며 plot에도 별다른 조치를 취하지 않는다.(참고 : group은 지정되지 않아도 colour(또는 color)가 지정되어 있으면 color에 맞추어 group인자를 내부적으로 생성한다. ggplot_build를 통해 확인해 볼 수 있다.)
3) 레이어마다 다른 데이터를 지정할 수 있다. "subcompact"자에 대해서만 geom_smooth()함수를 실행해 보자
ggplot(data = mpg, mapping = aes(displ, hwy))+
geom_point(aes(color=class))+
geom_smooth(
data = filter(mpg, class == "subcompact"),
se = FALSE
)

1.6.4 연습문제
6번
다음과 같은 그래프는 geom_point를 두 번 사용해서 그릴 수 있다.
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point(size = 4, color = "white") +
geom_point(aes(colour = drv))
1.7 통계적 변환
1) 다수의 그래프는 데이터셋의 원 값으로 플롯을 그린다. 막대 그래프와 같은 다른 그래프는 플롯으로 그릴 새로운 값을 데이터 셋에서 계산한다.
- 막대 그래프, 히스토그램, 빈도 다각형은 데이터를 bin으로 만든 후, 각 빈에 해당하는 점들의 개수인 도수를 플롯한다.
- 평활 차트들은 데이터에 모델을 적합한 후 모델을 이용한 예측값을 플롯한다.
- 박스 플롯은 분포의 로버스트(robust)한 요약값을 계산한 후 특수한 형태의 박스로 표시한다.
그래프에 사용할 새로운 값을 계산하는 알고리즘은 통계적 변환의 줄임말인 스탯(stat)이라고 부른다.
<예시> - geom_bar
## 원 데이터 ##
> glimpse(diamonds)
Observations: 53,940
Variables: 10
$ carat <dbl> 0.23, 0.21, 0.23, 0....
$ cut <ord> Ideal, Premium, Good...
$ color <ord> E, E, E, I, J, J, I,...
$ clarity <ord> SI2, SI1, VS1, VS2, ...
$ depth <dbl> 61.5, 59.8, 56.9, 62...
$ table <dbl> 55, 61, 65, 58, 58, ...
$ price <int> 326, 326, 327, 334, ...
$ x <dbl> 3.95, 3.89, 4.05, 4....
$ y <dbl> 3.98, 3.84, 4.07, 4....
$ z <dbl> 2.43, 2.31, 2.31, 2....> library(tidyverse)
> p1 <- ggplot(data = diamonds, aes(x=cut))+
+ geom_bar()
> p1
> p1_data <- as.data.frame(ggplot_build(p1)$data)
## geom_bar() 플롯 후 생성된 데이터 형태 ##
> glimpse(p1_data)
Observations: 5
Variables: 15
$ y <dbl> 1610, 4906, 12082, ...
$ count <dbl> 1610, 4906, 12082, ...
$ prop <dbl> 1, 1, 1, 1, 1
$ x <int> 1, 2, 3, 4, 5
$ PANEL <fct> 1, 1, 1, 1, 1
$ group <int> 1, 2, 3, 4, 5
$ ymin <dbl> 0, 0, 0, 0, 0
$ ymax <dbl> 1610, 4906, 12082, ...
$ xmin <dbl> 0.55, 1.55, 2.55, 3...
$ xmax <dbl> 1.45, 2.45, 3.45, 4...
$ colour <lgl> NA, NA, NA, NA, NA
$ fill <chr> "grey35", "grey35",...
$ size <dbl> 0.5, 0.5, 0.5, 0.5,...
$ linetype <dbl> 1, 1, 1, 1, 1
$ alpha <lgl> NA, NA, NA, NA, NAgeom_bar는 스탯 함수로 stat_count를 사용한다. 해당 함수를 통해서 count, prop과 같은 새로운 변수를 생성한다. help 페이지를 살펴보면 새로운 변수로 무엇을 생성하는지 아래처럼 알 수 있다(?geom_bar)
Computed variables
count : number of points in bin
prop : groupwise proportion
2) geom과 stat함수는 서로 바꿔서 사용할 수 있다. geom_bar 대신 stat_count를 사용할 수 있다는 말이다.
library(tidyverse)
ggplot(data = diamonds)+
stat_count(aes(x=cut))모든 지옴은 기본 스탯이 있고 모든 스탯은 기본 지옴이 있기 때문에 가능하다. 일반적으로 내부 통계적 변환에 신경 쓸 필요 없이 지옴을 사용할 수 있다. 명시적으로 스탯을 사용해야 하는 이유는 세 가지가 있다
1) 기본 스탯을 덮어쓰고 싶은 경우 (데이터 그대로 사용하고 싶은 경우 geom 함수 내부에 stat = "identity"를 사용해 주면 된다.)
2) 변환된 변수에서 기본 매핑 대신 다른 것을 사용하고 싶은 경우(기본 : 빈도 -> 비율)
library(tidyverse)
ggplot(data = diamonds)+
stat_count(aes(x=cut, y = ..prop.., group = 1))

주의할 점은 group = 1이라는 값을 줘서 모든 데이터들이 하나의 그룹임을 알려줘야 ..prop..의 값도 전체에서 각 범주의 비율이 얼마나 되는지 계산해 준다. group을 지정해주지 않으면 각 범주별로 group이 지정되기 때문에 각기 다른 group 내에서 count값의 비율인 prop변수는 당연히 모두 1이 된다.

3) stat_summary 사용하는 경우 (중요)
library(tidyverse)
ggplot(data = diamonds)+
stat_summary(
aes(x = cut, y = depth),
fun.ymin = min,
fun.ymax = max,
fun.y = median,
geom = "pointrange"
)
stat_summary함수는 기본 지옴인 "pointrange"가 원하는 인자들은 fun.ymin, fun.ymax, fun.y로 다양한데 위 코드를 보면 각각의 인자들 마다 적용할 함수를 지정해 주었다. 지정된 함수들은 x축 별 y값 depth에 대해서 지정된 함수를 수행한 후에 해당 인자의 값으로 사용한다. 마찬가지로 fun.data라는 인자도 있는데, 해당 인자도 x축 별 y값에 대해서 함수를 적용하고 해당 값을 적절한 컬럼에 반환하여 최종적으로 데이터프레임 형태로 인자를 반환한다. 아래 예시 좀더 자세한 내용은 추후에 정리해야 할 것 같다 (R cookbook 참고하는 것도 좋을 듯)

ggplot2에는 20개가 넘는 스탯이 있다. 각 스탯은 함수이고 도움말 또는 ggplot2 치트시트를 통해서 살펴볼 수 있다.
<stat_summary 인자 fun.data 활용>
library(tidyverse)
## fun.data, fun.args를 활용해 stat_summary 사용하기 ##
p1 <- ggplot(mtcars, aes(cyl, mpg)) +
stat_summary(fun.y = "mean", geom = "point")
p1
mean_median <- function(y_group_by_cyl){
df <- data.frame(y = mean(y_group_by_cyl),
size = median(y_group_by_cyl))
}
p2 <- ggplot(mtcars, aes(cyl, mpg)) +
stat_summary(fun.data = "mean_median", geom = "point")
p2
위 코드를 보면 p1 은 fun.y를 "mean"으로 적용하여 cyl별 mpg의 값의 평균을 계산한다. 즉. x값을 group으로 하여 x값 별로 해당하는 y값들을 mean인자에 넘겨주고 평균을 계산한다.
p2는 fun.data를 사용하는 예시이다. "mean_median"함수를 작성했는데, 함수를 보면 x group 별 벡터로 주어지는 y값에 대해서 함수를 적용하여 요약값을 산출하도록 되어 있는데 y값에는 mean을, size에는 median을 적용해서 결론적으로 x값 별 요약된 y값을 plot하고 x값 별 median 값이 x값 별 포인트의 사이즈를 결정한다.

fun.args는 fun.data에 적용되는 함수가 요약값들을 산출할 때 필요한 인자들을 리스트 형태로 넘겨주는 것이다. 아래 코드처럼 fun.data을 통해서 point의 size 값을 median을 지정하여 너무 크게 plot 된다. fun.data에 적용된 함수를 약간 수정하여 point의 크기를 줄이기로 하자. 이럴 땐 fun.data에 지정된 함수에 plot을 그리기 위한 인자들을 넘겨주어야 하는데 해당 역할을 수행한다. 아래 코드와 plot을 보면 글이 이해될 것이다.
mean_median <- function(y_group_by_cyl, median_low){
df <- data.frame(y = mean(y_group_by_cyl),
size = median(y_group_by_cyl/median_low))
}
p2 <- ggplot(mtcars, aes(cyl, mpg)) +
stat_summary(fun.data = "mean_median",
geom = "point",
fun.args = list(median_low = 2))
p2
fun.data를 수행하는 함수를 작성할 때는 x값 별 y값을 벡터로 받아 하나의 행을 가지는 data.frame을 반환하도록 하고 추가적인 인자를 생성하여 넘겨주고 싶은 경우에는 반환되어야 할 data.frame에 열을 추가한다. 이때 열 이름은 각각의 geom 함수가 필요로 하는 인자들을 정의하면 된다. 각 인자들을 상황에 따라 조금씩 수정하여 plot하고 싶은 경우에는 위 예시처럼 fun.args를 fun.data에 지정된 함수에 리스트 형태로 인자를 넘겨 plot을 수정하면 된다..
지금의 설명이 누구를 이해시키기 위한 용도이기 보다 본인의 지식을 위한 정리 용도 이므로 혹시 궁금하다면 댓글을 남겨주면 아는 한에서 설명드리도록 하겠다.
1.7.1 연습문제
1번
stat_summary와 연관된 기본 지옴은 무엇인가? 스탯 함수 대신 이 지옴 함수를 사용하여 어떻게 이전 플롯을 다시 생성하겠는가?
##############이전 함수###########
library(tidyverse)
ggplot(data = diamonds)+
stat_summary(
aes(x = cut, y = depth),
fun.ymin = min,
fun.ymax = max,
fun.y = median,
geom = "pointrange"
)ggplot(data = diamonds)+
geom_pointrange(aes(cut, depth),
fun.ymin = min,
fun.ymax = max,
fun.y = median,
stat = "summary")geom_pointrange 함수는 stat = "identity"이므로 stat = "summary"를 부여하고, geom_pointrange의 기본 인자에 해당하지 않는 fun.ymin, fun.ymax, fun.y의 세가지 인자들은 ...으로 인식돼서 stat_summary함수에 인자로 전달되고, stat_summary함수의 역할데로 x축 별 y값들의 fun.min, fun.max, fun.y를 수행하여 플랏을 위한 데이터를 만든다 (중요)
> ggplot_build(p1)$data
[[1]]
x group y ymin ymax PANEL colour size linetype shape fill alpha stroke
1 1 1 65.0 43.0 79.0 1 black 0.5 1 19 NA NA 1
2 2 2 63.4 54.3 67.0 1 black 0.5 1 19 NA NA 1
3 3 3 62.1 56.8 64.9 1 black 0.5 1 19 NA NA 1
4 4 4 61.4 58.0 63.0 1 black 0.5 1 19 NA NA 1
5 5 5 61.8 43.0 66.7 1 black 0.5 1 19 NA NA 1
2번
geom_col의 역할은 무엇인가? geom_bar와 어떻게 다른가
geom_col은 stat_identity를 사용하여 데이터의 값 그대로 사용하고 geom_bar는 stat_count가 기본 stat함수로 사용하여 x축 별 빈도를 y의 기본값으로 사용한다. 그런데 stat_count함수를 이용할 때 해당 함수가 x축 별 빈도만을 계산하는 것이 아닌 prop값도 계산해 줘서 ..prop..형태로 사용 가능하다
3번
대부분의 지옴과 스탯은 쌍을 이루어 거의 항상 함께 사용된다. 도움말을 읽고 모든 쌍의 목록을 만들어라. 공통점은 무엇인가?
| geom | stat |
| geom_bar() | stat_count() |
| geom_bin2d() | stat_bin_2d() |
| geom_boxplot() | stat_boxplot() |
| geom_contour() | stat_contour() |
| geom_count() | stat_sum() |
| geom_density() | stat_density() |
| geom_density_2d() | stat_density_2d() |
| geom_hex() | stat_hex() |
| geom_freqpoly() | stat_bin() |
| geom_histogram() | stat_bin() |
| geom_qq_line() | stat_qq_line() |
| geom_qq() | stat_qq() |
| geom_quantile() | stat_quantile() |
| geom_smooth() | stat_smooth() |
| geom_violin() | stat_violin() |
| geom_sf() | stat_sf() |
| geom | dafault stat | shared docs |
| geom_abline() | ||
| geom_hline() | ||
| geom_vline() | ||
| geom_bar() | stat_count() | x |
| geom_col() | ||
| geom_bin2d() | stat_bin_2d() | x |
| geom_blank() | ||
| geom_boxplot() | stat_boxplot() | x |
| geom_countour() | stat_countour() | x |
| geom_count() | stat_sum() | x |
| geom_density() | stat_density() | x |
| geom_density_2d() | stat_density_2d() | x |
| geom_dotplot() | ||
| geom_errorbarh() | ||
| geom_hex() | stat_hex() | x |
| geom_freqpoly() | stat_bin() | x |
| geom_histogram() | stat_bin() | x |
| geom_crossbar() | ||
| geom_errorbar() | ||
| geom_linerange() | ||
| geom_pointrange() | ||
| geom_map() | ||
| geom_point() | ||
| geom_map() | ||
| geom_path() | ||
| geom_line() | ||
| geom_step() | ||
| geom_point() | ||
| geom_polygon() | ||
| geom_qq_line() | stat_qq_line() | x |
| geom_qq() | stat_qq() | x |
| geom_quantile() | stat_quantile() | x |
| geom_ribbon() | ||
| geom_area() | ||
| geom_rug() | ||
| geom_smooth() | stat_smooth() | x |
| geom_spoke() | ||
| geom_label() | ||
| geom_text() | ||
| geom_raster() | ||
| geom_rect() | ||
| geom_tile() | ||
| geom_violin() | stat_ydensity() | x |
| geom_sf() | stat_sf() | x |
| stat | default geom | shared docs |
| stat_ecdf() | geom_step() | |
| stat_ellipse() | geom_path() | |
| stat_function() | geom_path() | |
| stat_identity() | geom_point() | |
| stat_summary_2d() | geom_tile() | |
| stat_summary_hex() | geom_hex() | |
| stat_summary_bin() | geom_pointrange() | |
| stat_summary() | geom_pointrange() | |
| stat_unique() | geom_point() | |
| stat_count() | geom_bar() | x |
| stat_bin_2d() | geom_tile() | x |
| stat_boxplot() | geom_boxplot() | x |
| stat_countour() | geom_contour() | x |
| stat_sum() | geom_point() | x |
| stat_density() | geom_area() | x |
| stat_density_2d() | geom_density_2d() | x |
| stat_bin_hex() | geom_hex() | x |
| stat_bin() | geom_bar() | x |
| stat_qq_line() | geom_path() | x |
| stat_qq() | geom_point() | x |
| stat_quantile() | geom_quantile() | x |
| stat_smooth() | geom_smooth() | x |
| stat_ydensity() | geom_violin() | x |
| stat_sf() | geom_rect() | x |
4번
stat_smooth는 어떤 변수를 계산하는가? 이 동작을 제어하는 파라미터들은 무엇인가?
아래와 같은 값을 계산한다.
-
y: predicted value
-
ymin: lower value of the confidence interval
-
ymax: upper value of the confidence interval
-
se: standard error
geom_smooth를 컨트롤하는 인자들은 아래와 같다
-
method: the method used to
-
formula: 포물려는 smooth 곡선을 그리기 위해 제공되는 모델의 형태를 나타낸 것이다. ex. y ~ x. y ~ poly(x,2), y ~ log(x)
-
na.rm
5번
우리는 비율 막대 그래프에서 group=1이라고 설정해야 하는 경우가 있다. 왜 그런가? 바꿔 말하면 다음 두 그래프이 문제는 무엇인가?
ggplot(data = diamonds) +
geom_bar(aes(x = cut, y = ..count.. / sum(..count..), fill = color))

$data[[1]]
fill y count prop x PANEL group ymin
1 #FDE725FF 0.002206155 119 1 1 1 7 0.000000000
2 #8FD744FF 0.005450501 175 1 1 1 6 0.002206155
3 #35B779FF 0.011067853 303 1 1 1 5 0.005450501
4 #21908CFF 0.016889136 314 1 1 1 4 0.011067853
5 #31688EFF 0.022673341 312 1 1 1 3 0.016889136
.....생략.....명령어를 실행하면 위에 있는 그래프를 그리고, 거기에 사용된 데이터는 그 아래에 있는 데이터와 같다.(일부 생략) 데이터를 잘 살펴보면 x축인 cut 별, fill에 의해 나눠진 group별 count가 계산이 되어 있고 y값을 ..count../sum(..coun..)와 같이 계산했기에, x축인 cut 별, fill에 의해 나눠진 group별 count를 sum(count)로 나누어 y값을 계산했기에 위와 같은 그래프가 그려지게 된다.
꽉찬 비율 막대가 보고 싶다면 아래와 같이 코드를 작성하면 된다.
ggplot(mtcars,aes(x=factor(cyl),fill=factor(gear)))+
geom_bar(position="fill")+
geom_text(aes(label=..count..),stat='count',position=position_fill(vjust=0.5))데이터 그래프는 아래와 같다. geom_text코드를 보면, cyl별 gear별 count가 구해지고 해당 count를 label로 지정했다. 여기서 끝났다면 label의 위치도 count의 크기에 따라서 결정됐겠지만, position_fill이라는 함수에 의해서 label로 지정된 count의 위치를 결정하는 y값에 변화를 줘서 아래와 같은 y값이 결정된다. (여기서 position_fill이 y값을 어떻게 변경하는지는 잘 모르겠다.) (어렵당!!..)
[[1]]
fill y count prop x PANEL group ymin ymax
1 #619CFF 0.1818182 2 1 1 1 3 0.0000000 0.1818182
2 #00BA38 0.9090909 8 1 1 1 2 0.1818182 0.9090909
3 #F8766D 1.0000000 1 1 1 1 1 0.9090909 1.0000000
4 #619CFF 0.1428571 1 1 2 1 6 0.0000000 0.1428571
5 #00BA38 0.7142857 4 1 2 1 5 0.1428571 0.7142857
6 #F8766D 1.0000000 2 1 2 1 4 0.7142857 1.0000000
7 #619CFF 0.1428571 2 1 3 1 8 0.0000000 0.1428571
8 #F8766D 1.0000000 12 1 3 1 7 0.1428571 1.0000000
xmin xmax colour size linetype alpha
1 0.55 1.45 NA 0.5 1 NA
2 0.55 1.45 NA 0.5 1 NA
3 0.55 1.45 NA 0.5 1 NA
4 1.55 2.45 NA 0.5 1 NA
5 1.55 2.45 NA 0.5 1 NA
6 1.55 2.45 NA 0.5 1 NA
7 2.55 3.45 NA 0.5 1 NA
8 2.55 3.45 NA 0.5 1 NA
[[2]]
fill y label count prop x width PANEL group ymax
1 #619CFF 0.09090909 2 2 1 1 0.9 1 3 0.1818182
2 #00BA38 0.54545455 8 8 1 1 0.9 1 2 0.9090909
3 #F8766D 0.95454545 1 1 1 1 0.9 1 1 1.0000000
4 #619CFF 0.07142857 1 1 1 2 0.9 1 6 0.1428571
5 #00BA38 0.42857143 4 4 1 2 0.9 1 5 0.7142857
6 #F8766D 0.85714286 2 2 1 2 0.9 1 4 1.0000000
7 #619CFF 0.07142857 2 2 1 3 0.9 1 8 0.1428571
8 #F8766D 0.57142857 12 12 1 3 0.9 1 7 1.0000000
xmin xmax ymin colour size angle hjust vjust alpha family
1 1 1 0.0000000 black 3.88 0 0.5 0.5 NA
2 1 1 0.1818182 black 3.88 0 0.5 0.5 NA
3 1 1 0.9090909 black 3.88 0 0.5 0.5 NA
4 2 2 0.0000000 black 3.88 0 0.5 0.5 NA
5 2 2 0.1428571 black 3.88 0 0.5 0.5 NA
6 2 2 0.7142857 black 3.88 0 0.5 0.5 NA
7 3 3 0.0000000 black 3.88 0 0.5 0.5 NA
8 3 3 0.1428571 black 3.88 0 0.5 0.5 NA
fontface lineheight
1 1 1.2
2 1 1.2
3 1 1.2
4 1 1.2
5 1 1.2
6 1 1.2
7 1 1.2
8 1 1.21.8 위치 조정
library(tidyverse)
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, fill = clarity))위 코드의 geom_bar는 디폴트 position이 "stack"이다. 즉. x축 별로 막대 누적이 자동으로 이뤄진다. 누적막대를 원하지 않는다면 "identity", "dodge", "fill"중 하나를 position으로 사용하면 된다. bar 플롯에서는 "identity"가 유용하지 않으므로 alpha 인자를 추가로 활용해 주면 좋다.
- position = "dodge" 위치 그대로
- position = "fill" 비율 막대
위치 조정에 좀 더 알고 싶다면 ?position_dodge, ?position_fill, ?position_identity, ?position_fitter, ? position_stack
1.8.1 연습문제
2번
geom_jitter에서 지터의 정도를 제어하는 파라미터들은 무엇인가?
- width
- height
3번
geom_jitter, geom_count의 차이는 무엇인가.
goem_jitter는 랜덤한 값을 더해서 점의 위치를 퍼트리는 것이지만, geom_count는 동일한(x,y)점에 대해서 count해서 점의 크기를 나타내는데 단점은 점이 큰 경우에 주변의 점을 가리게 된다. count 보다 jitter를 사용하는게 더 좋아보인다.
4번
geom_boxplot의 위치 조정 기본값은 무엇인가? mpg 데이터셋 시각화를 생성하여 이를 표시하라.
디폴트 position은 "dodge2"이다. "dodge2"는 position_dodge2의 short_cut이다. short_cut은 일종의 축약어라고 생각하면 된다. position_dodge2의 조정없이 기본 그대로 사용하고자 할 때 "dodge2"를 position 인자에 넘겨주면 된다.
1.9 좌표계
ggplot의 기본 좌표계는 x ,y의 위치가 독립적으로 움지깅는 데카르트(Cartesian)좌표계이다. 이것 말고도 다른 좌표계들이 많다.
coord_flip은 x와 y축을 바꾼다. 수평 박스플롯이 필요할 때 유용하다.
coord_quickmap()을 하면 지도에 맞게 가로세로 비율이 설정된다. ggplot2로 공간 데이터를 플롯할 때 매우 중요하다(이 책에서는 다루지 않는다)
아래와 같은 플롯을 x축, y축 비율을 지도에 맞게 설정한다.


코드는 아래와 같다
ggplot(nz, aes(long, lat, group = group))+
geom_polygon(fill = "white", colour = "black")+
coord_quickmap()1.9.1 연습문제
1번
coord_polar를 이용해서 누적 막대 그래프를 파이 차트로 바꾸라
아래 코드를 사용하면
ggplot(mpg, aes(x = factor(1), fill = drv)) +
geom_bar(width = 1) +
coord_polar(theta = "y")
coord_polar에서 theta = "y"가 없으면 bulls-eye chart를 그려준다.
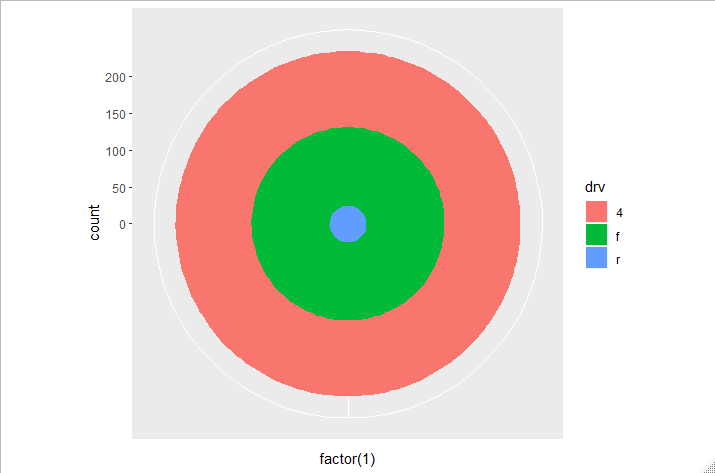
2번
labs는 어떤 역할을 하는가? 아래 코드를 보자
labs(
y = "Highway MPG",
x = "Class",
title = "Highway MPG by car class",
subtitle = "1999-2008",
caption = "Source: http://fueleconomy.gov"
)3번
coord_quickmap, coord_map의 차이점
coord_quickmap은 지구의 곡률을 계산하지 않은 근사치를 빠르게 지도로 그릴 수 있게 해주는 반면 coord_map은 메르카토르 곡률을 이용하여 3차원의 공간을 2차원의 지도로 만들어준다.
4번
coord_fixed의 역할

위와 같은 plot은 x축의 5만큼의 거리와 y축의 5만큼의 거리가 다르다. coord_fixed를 사용해 주면 아래와 같이 동일하게 만들어준다. 내가 생각하기에 장단점은 위 플롯은 공간을 효율적으로 사용할 수 있지만 x축 y축의 같은 값의 거리가 다르다는 것이고 coord_fixed는 실제 값의 관계를 좀 더 명확하게 알 수 있지만, 공간을 효율적으로 이용하지 못한다.

1.10 복습
stat_count함수를 통해서 geom_bar그래프를 그려볼 것이다. 플롯은 ggplot을 통해서 데이터와 x축을 지정해 주며, stat_count가 지정된 x축 변수에 따라서 플롯에 사용할 데이터를 만들어 준다. 단순히 x축만 지정해주면 x축 별 count를 세고, fill 인자가 지정되어 있으면 fill에 따라 x축 각각의 값이 여러 개가 된다. 아래 코드와 그래프를 보면 쉽게 이해될 것
> p1 <- ggplot(data = diamonds, aes(cut))+
+ stat_count(geom = "bar", position = "stack")
> p1
> ggplot_build(p2)$data
[[1]]
fill y count prop x PANEL group ymin ymax xmin xmax colour size linetype alpha
1 #FDE725FF 9 9 1 1 1 8 0 9 0.55 1.45 NA 0.5 1 NA
2 #9FDA3AFF 26 17 1 1 1 7 9 26 0.55 1.45 NA 0.5 1 NA
3 #4AC16DFF 95 69 1 1 1 6 26 95 0.55 1.45 NA 0.5 1 NA
4 #1FA187FF 265 170 1 1 1 5 95 265 0.55 1.45 NA 0.5 1 NA
5 #277F8EFF 526 261 1 1 1 4 265 526 0.55 1.45 NA 0.5 1 NA
6 #365C8DFF 934 408 1 1 1 3 526 934 0.55 1.45 NA 0.5 1 NA
7 #46337EFF 1400 466 1 1 1 2 934 1400 0.55 1.45 NA 0.5 1 NA
8 #440154FF 1610 210 1 1 1 1 1400 1610 0.55 1.45 NA 0.5 1 NA
9 #FDE725FF 71 71 1 2 1 16 0 71 1.55 2.45 NA 0.5 1 NA
10 #9FDA3AFF 257 186 1 2 1 15 71 257 1.55 2.45 NA 0.5 1 NA
11 #4AC16DFF 543 286 1 2 1 14 257 543 1.55 2.45 NA 0.5 1 NA
12 #1FA187FF 1191 648 1 2 1 13 543 1191 1.55 2.45 NA 0.5 1 NA
13 #277F8EFF 2169 978 1 2 1 12 1191 2169 1.55 2.45 NA 0.5 1 NA
14 #365C8DFF 3729 1560 1 2 1 11 2169 3729 1.55 2.45 NA 0.5 1 NA
15 #46337EFF 4810 1081 1 2 1 10 3729 4810 1.55 2.45 NA 0.5 1 NA
16 #440154FF 4906 96 1 2 1 9 4810 4906 1.55 2.45 NA 0.5 1 NA
17 #FDE725FF 268 268 1 3 1 24 0 268 2.55 3.45 NA 0.5 1 NA
18 #9FDA3AFF 1057 789 1 3 1 23 268 1057 2.55 3.45 NA 0.5 1 NA
19 #4AC16DFF 2292 1235 1 3 1 22 1057 2292 2.55 3.45 NA 0.5 1 NA
20 #1FA187FF 4067 1775 1 3 1 21 2292 4067 2.55 3.45 NA 0.5 1 NA
> p2 <- ggplot(data = diamonds, aes(cut, fill = clarity))+
+ stat_count(geom = "bar", position = "stack")
> p2
> ggplot_build(p2)$data
[[1]]
fill y count prop x PANEL group ymin ymax xmin xmax colour size linetype alpha
1 #FDE725FF 9 9 1 1 1 8 0 9 0.55 1.45 NA 0.5 1 NA
2 #9FDA3AFF 26 17 1 1 1 7 9 26 0.55 1.45 NA 0.5 1 NA
3 #4AC16DFF 95 69 1 1 1 6 26 95 0.55 1.45 NA 0.5 1 NA
4 #1FA187FF 265 170 1 1 1 5 95 265 0.55 1.45 NA 0.5 1 NA
5 #277F8EFF 526 261 1 1 1 4 265 526 0.55 1.45 NA 0.5 1 NA
6 #365C8DFF 934 408 1 1 1 3 526 934 0.55 1.45 NA 0.5 1 NA
7 #46337EFF 1400 466 1 1 1 2 934 1400 0.55 1.45 NA 0.5 1 NA
8 #440154FF 1610 210 1 1 1 1 1400 1610 0.55 1.45 NA 0.5 1 NA
9 #FDE725FF 71 71 1 2 1 16 0 71 1.55 2.45 NA 0.5 1 NA
10 #9FDA3AFF 257 186 1 2 1 15 71 257 1.55 2.45 NA 0.5 1 NA
11 #4AC16DFF 543 286 1 2 1 14 257 543 1.55 2.45 NA 0.5 1 NA
12 #1FA187FF 1191 648 1 2 1 13 543 1191 1.55 2.45 NA 0.5 1 NA
13 #277F8EFF 2169 978 1 2 1 12 1191 2169 1.55 2.45 NA 0.5 1 NA
14 #365C8DFF 3729 1560 1 2 1 11 2169 3729 1.55 2.45 NA 0.5 1 NA
15 #46337EFF 4810 1081 1 2 1 10 3729 4810 1.55 2.45 NA 0.5 1 NA
16 #440154FF 4906 96 1 2 1 9 4810 4906 1.55 2.45 NA 0.5 1 NA
17 #FDE725FF 268 268 1 3 1 24 0 268 2.55 3.45 NA 0.5 1 NA
18 #9FDA3AFF 1057 789 1 3 1 23 268 1057 2.55 3.45 NA 0.5 1 NA
19 #4AC16DFF 2292 1235 1 3 1 22 1057 2292 2.55 3.45 NA 0.5 1 NA
20 #1FA187FF 4067 1775 1 3 1 21 2292 4067 2.55 3.45 NA 0.5 1 NA
21 #277F8EFF 6658 2591 1 3 1 20 4067 6658 2.55 3.45 NA 0.5 1 NA
22 #365C8DFF 9898 3240 1 3 1 19 6658 9898 2.55 3.45 NA 0.5 1 NA
23 #46337EFF 11998 2100 1 3 1 18 9898 11998 2.55 3.45 NA 0.5 1 NA
24 #440154FF 12082 84 1 3 1 17 11998 12082 2.55 3.45 NA 0.5 1 NA
'R programming > R4DS (R for DataScience) ' 카테고리의 다른 글
| R4DS (R FOR DATASCIENCE) 6장 (0) | 2019.12.23 |
|---|---|
| R4DS (R for DataScience) 5장(4장 별 내용 없어 3장에 간단히 기록) (0) | 2019.12.10 |
| R4DS (R for DataScience) 3장 (0) | 2019.12.02 |
| R4DS (R for DataScience) 2장 (0) | 2019.11.27 |
| R4DS 서문 (0) | 2019.02.25 |


